Day 24 spark architecture
Check out our live web application for this program - https://newdaynewlearning.netlify.app/

[!NOTE] There is a game waiting for you today, the best/first answer can win an exciting gift🎁
- Click on the link : https://www.nytimes.com/games/wordle/index.html
- You will get a 6 chance to guess the 5-letter word correctly
More about me:
I am just a Colleague of your’ s, Learning and exploring how Math, Business, and Technology can help us to make better decisions in the field of data science.
- Check out my Second brain: https://medium.com/@ravikumar10593/
- Check out my Portfolio : Link
Topic : Spark Architecture
Article Source :
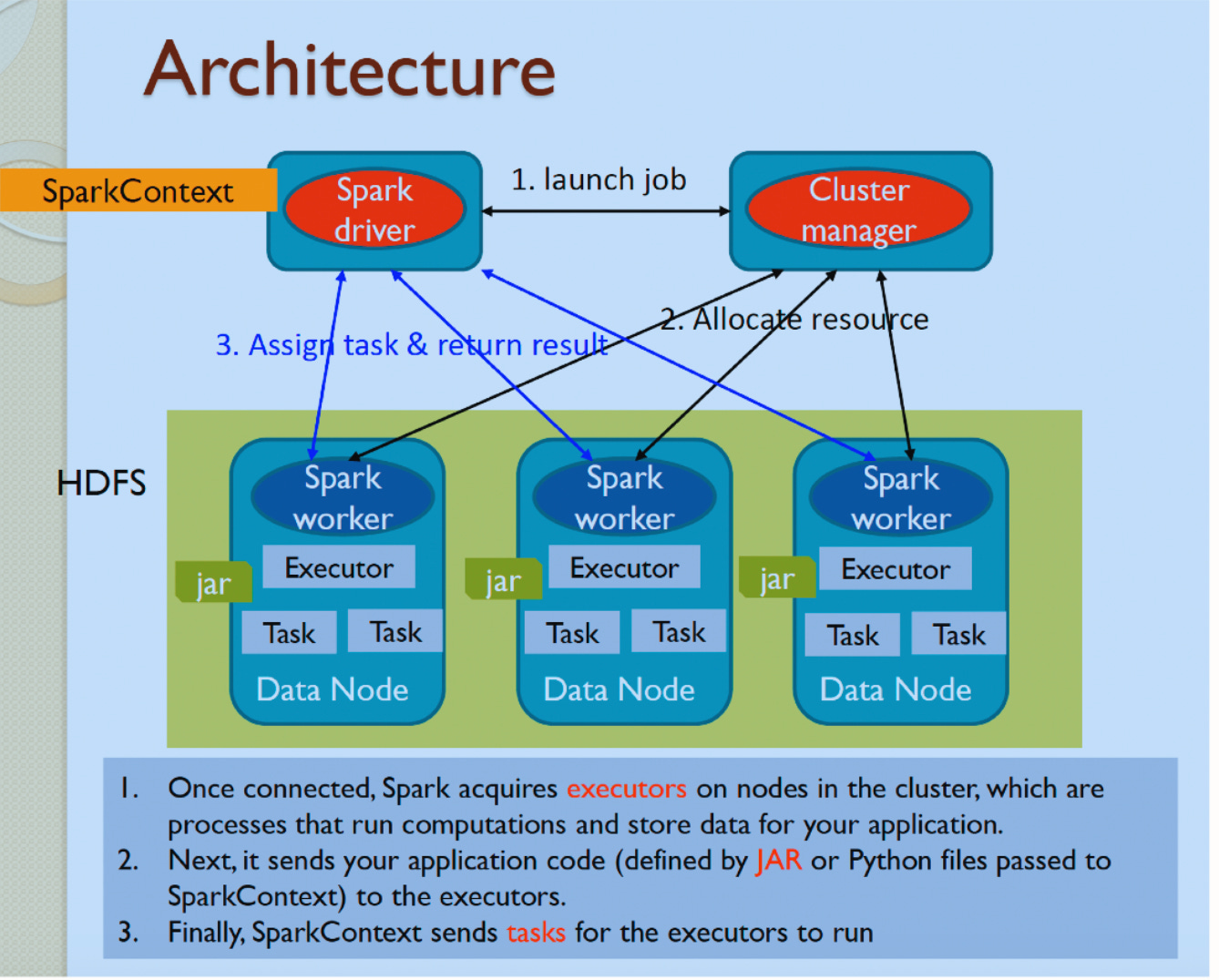
TL;DR : Components:
- SparkContext: The main entry point for Spark, responsible for connecting to the cluster, acquiring resources, and managing the execution of Spark jobs.
- Cluster Manager: Manages resources across the cluster (e.g., CPU, memory, storage) and allocates them to Spark applications. Spark supports various cluster managers like Standalone, YARN, and Kubernetes.
- Executors: Worker nodes in the cluster that execute individual tasks assigned by the Spark driver.
- Tasks: The smallest unit of work in Spark, responsible for executing specific operations on data partitions.
- Driver: The master node that orchestrates the execution of parallel operations on the cluster, converting user programs into tasks and scheduling them on executors.
Advantages of Spark’s Architecture
- In-memory processing makes Spark up to 100x faster than traditional MapReduce.
- Easily scales to process petabytes of data across distributed clusters.
- RDD lineage allows automatic recovery from node failures.
- Supports multiple languages, including Scala, Python, Java, and R.
- Works seamlessly with Hadoop, HDFS, and other big data tools.
Notes mentioning this note
Index page
[[Day 1 - MCP (Model Context Protocol)]] [[Day 2 - Change Data Capture (CDC)]] [[Day 3 - Small Language Model...